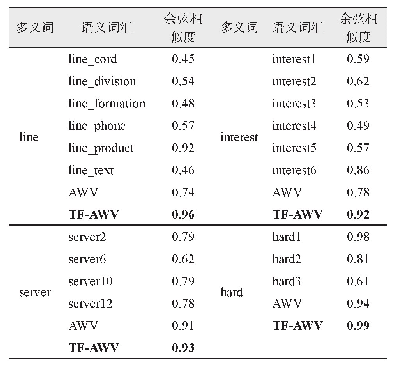
《表2 基于词向量的高频词、近义词》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于孪生网络的基金与受资助论文相关性判别模型构建研究》
word2vec是Mikolov等[12]于2013年提出的一种神经语言模型,使用Skip-Gram或CBOW(continu‐ous bag of words)模型预测上下文和中心词是否共现,能够充分捕获词的上下文语义、语法信息。word2vec模型将词汇表示为定长稠密向量的形式,词汇之间的语义相似度可以通过向量之间的距离或夹角余弦值衡量。本文采用腾讯AI Lab开源的800万中文词向量[13]作为预训练词向量。腾讯中文词向量在覆盖率、新鲜度及准确性上相较于其他公开数据有了大幅提升。首先通过Jieba分词工具对抓取的基金标题、论文标题和论文摘要进行分词,将腾讯词向量中不存在的词作为停用词删除,使用Skip-Gram模型在本文获取的语料上训练,最后得到长度为200维的词向量217260条。借助谷歌Em‐bedding Projector工具,我们将生成的词向量可视化表示,并查询了部分各学科的高频词的近义词,如表2所示。
| 图表编号 | XD00168289300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.24 |
| 作者 | 叶文豪、王东波、沈思、苏新宁 |
| 绘制单位 | 南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京农业大学信息科学技术学院、南京理工大学经济管理学院、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}