《表1 特征提取:面向多源关系数据的融合》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(1)特征提取.对各属性列数据进行特征提取,以衡量各列之间的相似程度.现有的文本特征提取方法,广义上可以分为两大类:(1)基于统计计算;(2)基于语义分析[35],二者均可运用于模式匹配算法中的特征提取.本文从统计学的角度,针对不同类型的数据,各自选取了平均长度、变异系数等具有代表性的多维统计量(见表1),将实例数据统一转化为数值特征,用于表征数据的句法特点.
| 图表编号 | XD00168233400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.20 |
| 作者 | 丁玥、王涓、卢卫、荣垂田、杜小勇 |
| 绘制单位 | 数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、天津工业大学计算机科学与技术学院、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




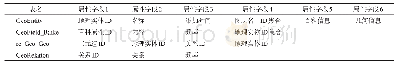
{kind=link}