《表6 基数估计方法比较:人工智能赋能的查询处理与优化新技术研究综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
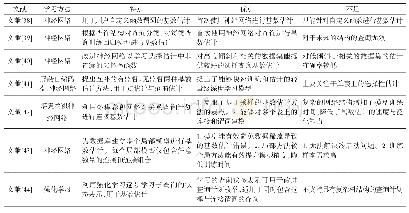
在基于代价的查询优化技术中,基数估计是评价查询计划的重要手段,其任务是估计查询执行计划中的每个操作符返回的元组数量[35]。基数估计的质量将直接影响查询计划的选择与查询优化器的性能。因此,高精度的基数估计十分重要。然而,大多数传统的估计方法都是基于如数据一致性与独立性等假设的统计模型,在真实数据集中,数据经常不满足假设,导致基数估计出现较大的错误[30,36-37],使优化器生成次优的查询计划。为了克服传统方法的限制,Lakshmi等人[38]第一个提出基于神经网络的用户自定义函数谓词基数估计算法,将自定义函数谓词转化为数值输入神经网络,预测谓词返回的元组数量。Malik等人[39]根据查询结构(连接条件、谓词属性等)利用决策树对查询分类,并对每类查询训练不同的回归模型进行基数估计。受到以上两个研究的启发,以及人工智能技术在其他查询优化问题的优秀表现,研究人员开始探索人工智能在基数估计问题上的潜力,相关文献比较如表6所示。
| 图表编号 | XD00165382600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 宋雨萌、谷峪、李芳芳、于戈 |
| 绘制单位 | 东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}