《表4 SVM常见并行化实现方式的对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(3)基于Spark的并行化。Spark是专为大规模数据处理而设计的快速通用的计算引擎,平台中拥有MLlib机器学习库,包含了分类算法、聚类算法、推荐算法等函数[83]。文献[84]根据Cascade SVM的思想,提出了一种基于Spark平台的并行化方案(SP-SVM)。实验结果表明,SP-SVM在损失很小精度的前提下减少了训练时间。文献[85]利用SVM结合Spark平台对Twitter推文进行文本分类,实现了一种检测交通实时事件的新方法。基于Spark的并行同样拥有较好的扩展性和容错率,但其优势也带来了问题。Spark在内存中计算远快于硬盘中,内存消耗大导致其需要更好的硬件设备支撑。MLlib的API丰富且调用简单,但不支持修改内部逻辑,大部分算法都只能简单调用而不能优化。表4列出了3种SVM常见并行化方式的对比。
| 图表编号 | XD00165378300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 林浩、李雷孝、王慧 |
| 绘制单位 | 内蒙古工业大学数据科学与应用学院、内蒙古自治区基于大数据的软件服务工程技术研究中心、内蒙古工业大学数据科学与应用学院、内蒙古自治区基于大数据的软件服务工程技术研究中心、内蒙古工业大学数据科学与应用学院、内蒙古自治区基于大数据的软件服务工程技术研究中心 |
| 更多格式 | 高清、无水印(增值服务) |

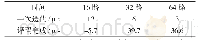



{kind=link}