《表3 算法的调参设置及最高整体精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
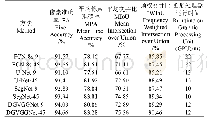
应用监督学习算法,建立各地的时空-内容特征与类型的映射。随机选取35%的地点作为训练样本,其余为测试样本。为取得最佳分类效果,研究选取几种最流行的监督学习算法进行对比:多层感知器(multilayer perceptron,MLP)算法,由输入、输出、隐藏层组成,利用反向传播技术完成模型训练[16];决策树(decision tree,DT)算法,通过属性测试构成节点,以自上而下的方式,尽可能减少结果的信息混乱程度[17];随机森林(random forest,RF)算法,通过批量建立决策树,一定程度上提高了泛化能力[18];支持向量机(support vector machine,SVM)算法,通过构建非线性函数,获取超平面进行决策[19]。以上算法经由weka[20]构建和参数调优,通过比较各算法在参数调优过程中取得的最佳整体精度(正确分类的样本数占总测试样本数的比值,见表3),最终选定MLP算法用于本研究。
| 图表编号 | XD00165018600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.30 |
| 作者 | 邱小宇、林杰 |
| 绘制单位 | 浙江大学地球科学学院、浙江大学地球科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}