《表2 参数设置:基于集成学习的不完备数据补全算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
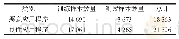
经过数据的残缺处理后,再次分裂数据集B得到包含残缺记录的数据集B1和非残缺数据集B2。模型中选择的基学习算法Zero、Mean、Median、Min、KNN、EM和RF,元级学习器选择RF算法作为集成。部分填补算法需要设置迭代参数,K近邻算法需设置近邻点k最大值k_max和k的迭代步长k_step,EM算法设置最大迭代次数和步长分别为Iter_max、iter_step,RF算法设置迭代最大树的个数、深度和步长分别为:depth_max、depth_step、estimators_max、estimators_step。在迭代过程中,计算基学习器每次填补的结果和数据集A对应索引记录之间的误差值,多次迭代优化误差,把优化后的基学习器的预测结果作为元级学习器RF的输入,同理设置元级学习器RF的迭代过程中相关参数值。需要说明一点的是,在本实验中,EM填补模型的数据分布全部假设是基于高斯分布的并没有进行严格的论证。表2给出本次试验中模型迭代过程相关参数的设置,具体内容如下,其中Zero、Mean、Median、Min、MICE默认填充,无参数设置。
| 图表编号 | XD00164974300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.20 |
| 作者 | 丁敬安、张欣海、胡博、周国民 |
| 绘制单位 | 杭州三汇数字信息技术有限公司、安徽工业大学管理科学与工程学院、中国电子科技集团公司电子科学研究院、社会安全风险感知与防控大数据应用国家工程实验室、浙江警察学院、浙江警察学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}