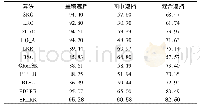
《表5 AR数据集中各算法在不同参数下识别率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于快速协同表示分类和组内预测重构系数向量l_2范数的人脸识别算法》
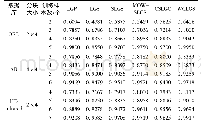
各算法实验结果如表5~8所示。表5展示了不同参数下各算法在AR数据集中的实验结果。可以看出,本文提出的FCRC_MC和FCRC_L2N算法的最高识别精度分别为90.271 8%和93.133 0%,与原算法仅相差0.035 765和0.007 153。表6展示了不同参数下各算法在extended Yale B数据集中的实验结果。可以看出,在不同参数下相同算法的识别精度不相同,本文提出的FCRC_MC和FCRC_L2N算法的最高识别精度为96.296 2%和98.518 5%,与原算法仅相差0.022 223,FCRC_L2N与CRC_RLS算法的识别精度相同。表7展示了不同参数下各算法在Yale数据集中的实验结果。可以看出,本文提出的FCRC_MC算法的最高识别精度为86.666 7%,与原算法仅相差0.111 11,FCRC_L2N算法的最高识别精度与原算法相同。表8展示了不同参数下各算法在ORL数据集中的实验结果。可以看出,本文提出的FCRC_MC算法的最高识别精度为89.333 3%,与原算法仅相差0.048 334,FCRC_L2N算法的最高识别精度与原算法相同。图5(e)~(h)展示了四个数据集中本文算法与CRC_RLS算法在识别精度上的差异。不难发现本文提出的算法同样具有较高的识别精度,表明了FCRC_MC和FCRC_L2N算法的有效性,其主要原因是本文提出的两种算法根据各自的分类准则能很好地将待识别样本的类别标号与目标组的组号进行关联匹配;本文在提出FCRC_MC算法后,通过引入组内预测重构系数向量的l2范数进一步改进提出FCRC_L2N算法,实验结果显示FCRC_L2N相比于FCRC_MC算法,在四个数据集中的识别精度分别提高了2.861 2%、2.222 3%、11.111 1%、4.833 4%。主要原因是基于组内预测重构系数向量的l2范数的分类准则相比基于预测重构系数向量最大值的分类准则,能使待识别样本的类别标号与目标组的组号产生更强的关联。
| 图表编号 | XD00163359400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.05 |
| 作者 | 梅伟健、裘国永 |
| 绘制单位 | 陕西师范大学计算机科学学院、陕西师范大学计算机科学学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}