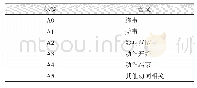
《表2 实验数据集:利用词项语义共现和社团划分发现微博热点事件》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
人工采集了新浪微博2017年1月~6月发表的微博作为实验数据。为保证与真实话题最大程度的一致性,采样时人工加入了适量的噪声数据,构造了一个共包含3 225条微博、8类热点事件的有噪声的微博数据集,其中描述事件的微博2 541条,噪声数据684条。对其进行数据清洗、分词、去停用词等预处理操作,并根据词项之间关系的紧密性进行了孤立词筛选,最终保留了28 600个词项。实验数据集如表2所示。
| 图表编号 | XD00163330000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 李晓红、孔文文、马堉垠、马慧芳 |
| 绘制单位 | 西北师范大学计算机科学与工程学院、西北师范大学计算机科学与工程学院、西北师范大学计算机科学与工程学院、西北师范大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}