《表6 BiLSTM-CRF实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在表5和表6的实验结果中,ENTL实体识别的P值、R值和F1值均较低,其主要原因是标注语料库中绝大部分ENTL实体具有嵌套性且标注数据占比较少,而实体的最大长度包含26个字符,平均字符数也达到8,为各类型实体中的最大值,CRF特征模板对包含较长字符的实体识别效果不佳,又由于数据规模的原因,加上BiLSTM模型的效果并没有很大的提升。BRI、ENT和ENTE类型实体具有相对较好的识别效果,三类评价指标均分布在0.64~0.88。综合标注数据和文本描述特性发现,BRI实体标注数量较少,预期的实验效果应该是比较理想,但是BRI实体涉及到较多的地名未登录词,拉低了预期的实验结果;ENT实体在检测文本中出现频次较高,占据了标注语料的40%以上,为模型训练提供更丰富的数据支撑;ENTE实体占据了标注语料的13%左右,但由于其嵌套性的影响,其实验结果指标不及ENT实体识别的结果指标。同时,ENT和ENTE描述的规范性对识别效果有一定帮助,但整体而言,其识别效果仍然有较大提升空间。DIS和UND类型实体的实验结果中精确率相对较好,但召回率和F值较低。分析其原因发现,由于检测文本描述特性,DIS和UND实体总体标注数量均相对较少,存在一定的标注数据不均衡性。除此以外,DIS实体涉及到一定数量的病害未登录词,UND实体也存在较多形式的否定描述,这些因素共同作用导致其识别效果不佳。由表7可知,BERT-BiLSTM-CRF的实验结果均差于CRF实验结果和BiLSTM-CRF实验结果。其主要原因在于实验过程中选用的BERT是基于大规模通用领域文本的预训练模型,而并不适用于桥梁检测领域的文本特性。
| 图表编号 | XD00163217500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 莫天金、李韧、杨建喜、李童、蒋仕新、李东 |
| 绘制单位 | 重庆交通大学信息科学与工程学院、重庆交通大学信息科学与工程学院、重庆交通大学信息科学与工程学院、重庆交通大学信息科学与工程学院、重庆交通大学信息科学与工程学院、重庆交通大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

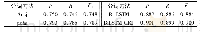




{kind=link}