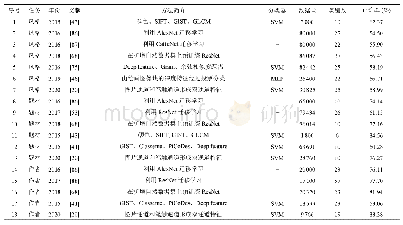
《表2 联合识别模型在ATIS数据集上的NLU性能结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文主要对最新的具有代表性的意图和语义槽联合识别的方法进行分析介绍,各模型在ATIS数据集上的性能如表2所示,评价指标包括语义槽填充F1值和意图识别准确率。第一组是RNN-LSTM模型,其中SD、MD分别代表在单领域、多领域上进行训练,Sep、Joint分别代表意图和语义槽独立建模、联合识别的方法,从实验结果可以看出无论是在单领域还是多领域,联合识别可以提高意图识别的准确率,但是语义槽填充F1值会降低,而从全局来看,联合多领域集成多任务的模型会提升识别语义框架的准确率。在第二组模型中,dropout为0.5,LSTM的单元数为128。基于双向RNN+Attention联合识别模型不要求编码器将所有输入信息都编码为一个固定长度的向量,而是在解码器的每一个时间步,都和编码器直接连接,通过对输入信息分配不同的权重聚焦式关注特定的部分,再与双向LSTM双向建模得到包含上下文语义信息的向量相结合,得到包含更丰富的语义向量表示,弥补了RNN对长距离依赖关系的不足,取得了较好的性能。双向RNN+Attention的模型与使用对齐输入的基于注意机制的编码器-解码器模型相比具有更高的计算效率,因为在模型训练期间,编码器-解码器模型读取输入序列两次,而双向RNN+Attention模型只读取输入序列一次。第三组是胶囊网络模型,dropout为0.2,胶囊网络通过动态路由机制改进了CNN的不足,捕获小概率的语义信息,保证了特征的完整性,而且重路由机制能利用意图识别的结果指导修正语义槽填充任务,性能有了一定的提升,同时证明了联合识别比独立建模效果更好,但其受模型复杂、参数多的影响导致计算速度较慢。第四组是BERT模型,目前在ATIS数据集上取得了最优性能,在该模型中Transformer设置为12层,dropout设置为0.1,包含768个隐藏状态和12个头部。基于BERT+CRF的联合识别模型用CRF取代Softmax分类器,但其性能与BERT相差不多,因为在序列标注任务中,标签之间是有依赖关系的,比如当采用BIO格式标注时,标签I应该在标签B之后出现,而不应该在标签B之前出现,CRF机制主要用于计算词标签之间的转移概率以进行标签全局优化。Tan等人[72]2018年提出使用深度注意力网络(Deep Attentional Neural Network)进行标注,在模型的顶层仅使用自注意力机制也能够学习到标签之间潜在的依赖信息,所以Transformer模型中的自注意机制已经对标签结构进行了充分建模,加入CRF后性能并没有提升。
| 图表编号 | XD00163030300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 王堃、林民、李艳玲 |
| 绘制单位 | 内蒙古师范大学计算机科学技术学院、内蒙古师范大学计算机科学技术学院、内蒙古师范大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}