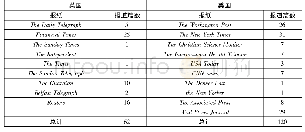
《表1 IR术语与传统软件工程术语的对照关系》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
IRBL方法关注的对象是缺陷报告和软件源码.从技术角度看,IRBL方法将缺陷定位任务看作是进行信息检索(IR)的过程.Rao等人[23]在2011年总结了信息检索领域的IR术语与软件工程领域在缺陷定位时所用术语的对照关系如表1所示.据此,IRBL任务执行过程可以描述如下:IRBL模型将缺陷报告看作查询(query),将报告中的文本进行分词处理组成查询语句.同时,将项目源码看作文档库(documents),对每份源文件进行预处理,构造出一个语料库.当收到缺陷报告时,从报告中构建查询语句并在文档库中检索(retrieval),根据查询语句与每个文档的相似度通过索引(index)将所有文档降序排列后反馈给开发者.在结果列表中,包含缺陷的文件(buggy files)尽可能排列在靠前的位置.开发者按照列表顺序对代码进行审查,可以在花费较少的工作量的情况下找到有缺陷的源文件,从而加速缺陷定位的进程.
| 图表编号 | XD00153549000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 郭肇强、周慧聪、刘释然、李言辉、陈林、周毓明、徐宝文 |
| 绘制单位 | 计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |



![表1 情报评估术语对照标准[13,15]](http://bookimg.mtoou.info/tubiao/gif/XDQB202008003_04400.gif)
{kind=link}