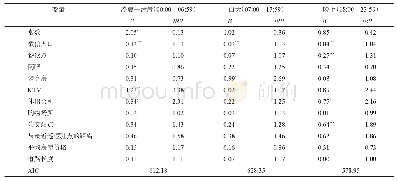
《表2 酒店被盗分星级负二项模型统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《建成环境对星级酒店内被盗的影响——以ZG市中心城区为例》
注:*、**、***分别表示P<0.1、P<0.05、P<0.01;括号内数据为发生率比(IRR)。下同。
本文选择2012—2014年每间星级酒店的盗窃案件总量作为因变量,酒店自身属性和建成环境指标为自变量,变量描述如表1。房间数和POI个数的标准差最大,说明数据分布较离散。因变量最大值为42,最小值为1,方差(39.21)远远大于均值(4.66),故排除泊松分布,选择负二项回归进行建模分析。首先对模型各自变量的共线性进行检验,一般认为,变量的方差膨胀因子(variance inflation factor,VIF)值越大,各自变量之间的共线性越强,要求VIF值小于10时各变量没有明显共线性[34]。经分析,自变量的VIF值均小于2.5,说明它们可以同时用于模型拟合。为控制房间数量对盗窃警情数量的影响,模型设置时,将各星级酒店的房间数量取对数设置为偏移量。经分析,总模型的似然比卡方值为64.18,P<0.001,各分类型和分时段模型的P值均为显著(表2),且Alpha值均显著大于0,说明数据适于负二项分布模型,自变量对于解释因变量是有意义的。
| 图表编号 | XD00149728600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.28 |
| 作者 | 张春霞、周素红、柳林、肖露子 |
| 绘制单位 | 广东工程职业技术学院管理工程学院、中山大学地理科学与规划学院广东省公共安全与灾害工程技术研究中心、广州大学地理科学学院公共安全地理信息分析中心、辛辛那提大学地理系、广州大学地理科学学院公共安全地理信息分析中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}