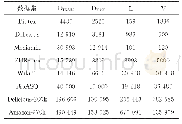
《表1 宏基因组数据集的特征》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对5个活性炭样品进行了宏基因组测序,其中G开头的样品为炭砂滤池样本,为验证数据的可靠性,GQ1和GQ2为平行样,C开头的为采用南水北调水源的另外一个水厂的活性炭滤池样本,平均每个样品产生14.06 Gbp清洁数据,总共鉴定到2 100 008个非冗余基因,表1为研究的基因组数据集特征。基因组分析采用MetaGeneMark预测蛋白质编码基因,基因注释基于KEGG数据库的GhostKoala完成[4]。此外,包括16S r RNA测序数据和宏基因组数据在内的所有原始测序数据已上传至NCBI的SRA数据库,登记号为:PRJNA546475。
| 图表编号 | XD00147420900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 韩梅、李云峰、游晓旭、路维嘉、赵洋洋、刘如铟 |
| 绘制单位 | 北京市自来水集团有限责任公司北京市供水水质工程技术研究中心、北京市自来水集团有限责任公司北京市供水水质工程技术研究中心、北京市自来水集团有限责任公司北京市供水水质工程技术研究中心、北京市自来水集团有限责任公司北京市供水水质工程技术研究中心、北京市自来水集团有限责任公司北京市供水水质工程技术研究中心、中国科学院大学资源与环境学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}