《表5 对测试集缺损标签数据恢复结果上的排序损失测试RL(↓)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
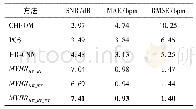
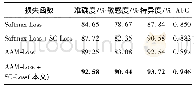
在实验过程中,对原始标签聚类,判断聚类个数K时,本文通过算法迭代,对比实验结果来获取K值,本文K值为22。ρ表示已知标签数占全标签数的百分比,ρ=100表示全标签。为了验证算法的有效性,采用测试集实验。表2至表5给出了本文算法和其他4种算法在13个数据集上的实验结果,数字加粗则表明在对比的算法中结果最好。其中算法一至算法四依次代表MAXIDE、LEML、ML-LRC、GLOCAL,算法五则是本文算法K-GLOCAL。
| 图表编号 | XD00144911800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.15 |
| 作者 | 王一宾、黄志强、程玉胜 |
| 绘制单位 | 安庆师范大学计算机与信息学院、安徽省高校智能感知与计算重点实验室、安庆师范大学计算机与信息学院、安庆师范大学计算机与信息学院、安徽省高校智能感知与计算重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}