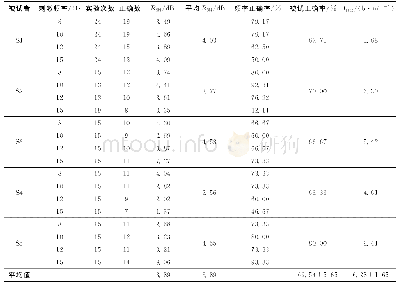
《表5 本文模型实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《预训练模型下融合注意力机制的多语言文本情感分析方法》
模型在不同情感类别上的准确率(Precision)、召回率(Recall)以及F1值如表5所示.可以看出,模型在Anger、Fear以及Surprise情感类别上的准确率远远大于召回率,造成这一问题的主要原因是数据类别的不平衡,通过分析语料发现,训练集中无情绪句子数量最多(1896),其次是Happiness(1842)和Sadness(1086),而其余类别数量较少,数据的不平衡将导致分类器偏向于占比较高的类别,对于Anger、Fear以及Surprise而言,由于本身类别较少,分类器则会倾向于将类别分类为无情绪(none),故式(24)中FNi较大,从而降低召回率.
| 图表编号 | XD00141223700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 胡德敏、褚成伟、胡晨、胡钰媛 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}