《表2 基于均匀回放的算法收敛后动作价值的误差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
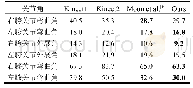
由表2和表3可见,当算法收敛到最优策略时,对于所有状态,动作期望回放算法最终的动作价值比均匀回放算法的动作价值要低,但都收敛到了最优策略,说明动作期望算法有效解决了Q学习算法的动作价值过估计问题.
| 图表编号 | XD00139181100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.30 |
| 作者 | 张峰、钱辉、董春茹、花强 |
| 绘制单位 | 河北省机器学习与计算智能重点实验室河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室河北大学数学与信息科学学院、河北省机器学习与计算智能重点实验室河北大学数学与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |



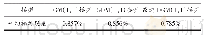

{kind=link}