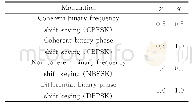
《表1(1,3)状态下的纳什Q值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
探索-开发方法在游戏中表现最佳,算法是随机选择动作的,因此探索和探索-开发的结果较为接近,探索-开发方法的优势在于通过贪婪策略增加了总的收益,开发的方法允许在搜索策略时增加一些探索,否则开发智能体会陷入相同动作的困境中,无休止的游戏下去[13];两种算法平均回报之间存在结果差异,平均回报可以反应性能,改进的算法通过近似值逼近值函数,不需要更新维护Q值表,能够更好地优化策略,获得较高的平均回报,提高算法的性能;改进的算法能够较快收敛,理论分析改进的算法具备收敛性,主要简化了传统纳什Q学习算法的复杂性,使用通用的方法更新策略,提高了算法的学习效率,这样可以保证算法尽快收敛。
| 图表编号 | XD00137221100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.16 |
| 作者 | 赵高长、刘豪、苏军 |
| 绘制单位 | 西安科技大学理学院、西安科技大学理学院、西安科技大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}