《表2 RQ1实验组织:强化学习方法在通信拒止战场仿真环境中多无人机目标搜寻问题上的适用性研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《强化学习方法在通信拒止战场仿真环境中多无人机目标搜寻问题上的适用性研究》
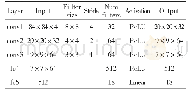
因此在第一个问题的实验组织中,我们围绕第2.5小节中的3个指标:目标获取数量均值和任务完成率,以及平均成功时间组织实验.具体如下:测试蓝方固定为随机游走策略,红方分别为备选算法DQN,L-QL,A3C,DPPO 4种算法中的一种.同时,设置对照组红蓝两方都为随机游走策略,共5组对抗,如表2所示,分别训练得到效果最好的模型.测试时,将强化学习算法与随机游走算法对比,观察在上述指标上的具体表现.
| 图表编号 | XD00137020600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.20 |
| 作者 | 汪亮、王文、王禹又、侯松林、乔裕哲、吴天珩、陶先平 |
| 绘制单位 | 南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}