《表2 模型预测误差对比:基于专家样本库和最小二乘支持向量机的配电网线损率预测模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于专家样本库和最小二乘支持向量机的配电网线损率预测模型》
%
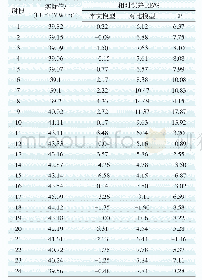
将模型M1、M2、M3的预测误差进行对比,结果见表2。由表2可知,线损率模型M2具有最差的预测精度,表明按照时间顺序采集的样本无法包含未来的运行状态。如在第120~150样本及180~210样本处,均不能实现精确的预测;与M2相比,线损率模型M3有一定的改进,表明随机选择方法得到的样本能够包含更多的运行状态,但在某些样本处(如第153~158样本处),仍存在较大的预测误差;线损率模型M1对训练样本集和测试样本集的预测误差均小于线损率模型M2、M3,即线损率模型M1具有更好的预测精度,表明通过DPSO搜索得到样本,能够包含更多的运行状态信息量。同时,通过表2中模型的预测误差eMAE、eRMSE、eNRMSE对比,也可得到相同的结论。可见,通过DPSO构建专家样本库来进行LS-SVM训练,能够得到更高精度的线损率预测模型。
| 图表编号 | XD00136801300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 丁忠安、高琛、蒋敏敏、林永春、吕游 |
| 绘制单位 | 国网福建省电力有限公司电力科学研究院、国网福建省电力有限公司电力科学研究院、国网信通亿力科技有限责任公司、国网信通亿力科技有限责任公司、华北电力大学新能源电力系统国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}