《表3 主要翻译模型比较:大规模知识图谱补全技术的研究进展》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
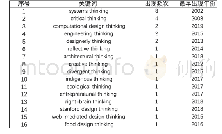
除了上述翻译模型之外,采用能量方程和神经网络方法的比较典型的学习模型还有语义匹配能量模型SME[23]、非结构化模型UM、潜在因素模型LFM[117]、循环矩阵模型CirE[118]、胶囊网络模型[119]等.SENN[120]则将头实体、尾实体和关系三者分开,在共享向量的同时做分别的预测学习即同时训练不同的3个神经网络.表3中对以上基本模型从评价函数进行了必要的比较,其中Ne,Nr分别是实体和关系的数量,Nt是知识图谱中三元组的数量,eh,et分别表示头实体和尾实体向量,m n分别表示实体和关系在嵌入空间中的维数,d为关系的平均聚类数量,s为张量的片数,k为神经网络中隐层中的结点数量.
| 图表编号 | XD00135961000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.20 |
| 作者 | 王硕、杜志娟、孟小峰 |
| 绘制单位 | 中国人民大学信息学院、河北大学机器学习与计算智能重点实验室、中国人民大学信息学院、中国人民大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}