《表2 DQN和A3C系列模型的每步训练时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(单位:ms/步)
本文比较了DQN与A3C系列算法在训练Agent玩部分Atari 2600游戏的每步训练时间,涉及的游戏包括Gravitar、StarGunner、TimePilot、Seaquest、Centipede、Breakout、NameThisGame、Amidar、Assault和Boxing,10种游戏的简要介绍如表1所示.在Intel Core i7-6800kCPU上DQN和A3C系列算法的训练时间如表2所示.表2数据展示了通过使用异步方法的4种A3C算法的每步训练时间相差不大,而传统DQN算法比A3C系列算法多耗费几倍的训练时间.由此可见,A3C系列算法在保证性能的情况下,利用异步方法极大缩短了模型的训练时间.
| 图表编号 | XD00134443900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 凌兴宏、李杰、朱斐、刘全、伏玉琛 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学江苏省计算机信息处理技术重点实验室、苏州大学计算机科学与技术学院、苏州大学江苏省计算机信息处理技术重点实验室、苏州大学计算机科学与技术学院、苏州大学江苏省计算机信息处理技术重点实验室、苏州大学计算机科学与技术学院、苏州大学江苏省计算机信息处理技术重点实验室、吉林大学符号计算与知识工程教育部重点实验室、软件新技术与产业化协同创新中心、常熟理工学院计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





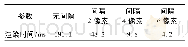
{kind=link}