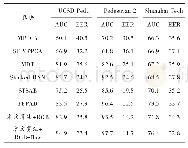
《表4 相同数据集上对比相关网络测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对比其他深度学习算法模型,将相同的数据集应用于SegNet、DeepLabv3、U-Net和改进的AA-SegNet网络进行实验。SegNet网络的解码器是使用上采样与卷积的过程,过度使用低级特征进行目标提取,会导致分割影像结果出现过度分割、小目标识别差现象。U_Net网络采用通道维度拼接融合方式,来增加特征的描述信息,存在过度使用低级特征的问题。DeepLabv3网络编码器采用空洞卷积生成任意维度的特征,并采用空间金字塔池化策略,在级联解码器进而恢复边界细节信息,也过度融合了低级特征。由于SegNet、DeepLabv3、U-Net缺乏注意力机制融合模块、增强型空间金字塔池化模块,一些低级特征被过度使用,导致识别图像结果建筑物过度分割并且小目标识别效果差,分割结果建筑物出现碎片化,参见图10(c)、(d)、(e)红框标示部分。在图10(c)中的红框标示中,AA-SegNet网络结果明显改善,说明空间注意力机制可以改善性能,降低碎片化,A-ASPP精准提取小目标。为定量比较所提出的AA-SegNet网络,在表4(测试集,包括4张尺寸为5 000×5 000图像)中分别给出了OA、F1得分、训练时间TT和识别时间RT,可以看出,AA-SegNet网络OA得分明显优于SegNet、DeepLabv3和U-net网络,其网络训练时间和识别时间都优于DeepLabv3和U-net网络(TT:15<21<25<55,RT:6<8<12<50),具有比较高的效率。总的来说,尽管存在很少一部分错误的建筑分类,见图11(b)和(d)红色框标示部分,但总体来说,AA-SegNet网络从高分辨率遥感影像中能够实现更好的建筑用地提取效果。
| 图表编号 | XD00133701800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.15 |
| 作者 | 宋廷强、李继旭、张信耶 |
| 绘制单位 | 青岛科技大学信息科学技术学院、青岛科技大学信息科学技术学院、珠海欧比特宇航科技股份有限公司人工智能研究院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}