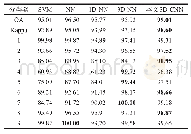
《表2 Isolet数据集的精度比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
Isolet spoken letter识别数据库有150名受试者,他们两次说出每个字母的名称。所描述的特征包括谱系数、轮廓特征,响音特征,前响音特征和后响音特征。受试者被分成5组,每组30个人,分别命名为Isolet1到Isolet5。在本研究中,使用Isolet2至Isolet5评估DADCL模型与SRC、KSVD、DKSVD、LC-KSVD2和JEDL的性能。对于每一组,通过改变3到30的标记口语字母的数量来检查性能,间隔为3,其余的用于测试。实验表明,本文的模型在α=10,β=0.01和γ=1时性能较训练和测试阶段的平均运行时间。从表2得到以下观察结果:(1)可以看出算法具有性能优势,即DADCL可以得到比其他更好的结果;(2)对于运行时间,最小化分类残差的SRC和KSVD都比使用SR的方法慢。尽管DADCL需要从训练阶段获得分类器,DADCL的实际运行时间仍与LCKSVD2和JEDL的实际运行时间相当,因为通过使用DADCL的解析字典P进行的测试过程非常高效。
| 图表编号 | XD00133687100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.15 |
| 作者 | 李巧、陈花竹、杨春雨、李丹 |
| 绘制单位 | 西安电子科技大学数学与统计学院、西安电子科技大学数学与统计学院、西安电子科技大学数学与统计学院、西安电子科技大学数学与统计学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}