《表1 专利文本数据集:基于BERT+ATT和DBSCAN的长三角专利匹配算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于BERT+ATT和DBSCAN的长三角专利匹配算法》
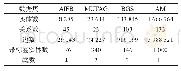
BERT的词向量模型的训练语料THUCNews中文数据集。THUCNews是根据新浪新闻RSS订阅频道2005至2011年间的新闻数据筛选得到,包含74万篇新闻文档(2.2GB),均为UTF-8纯文本格式。专利向量的聚类模型采用DBSCAN模型。
| 图表编号 | XD00132770900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 曹旭友、周志平、王利、赵卫东 |
| 绘制单位 | 同济大学电子与信息工程学院、同济大学电子与信息工程学院、同济大学电子与信息工程学院、同济大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}