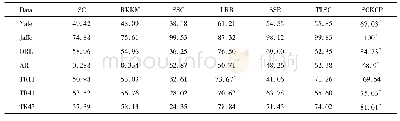
《表2 部分数据点的聚类结果统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
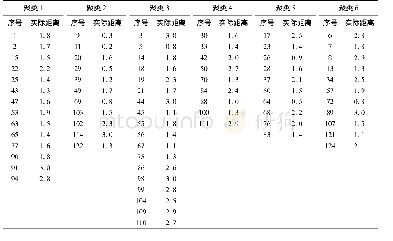
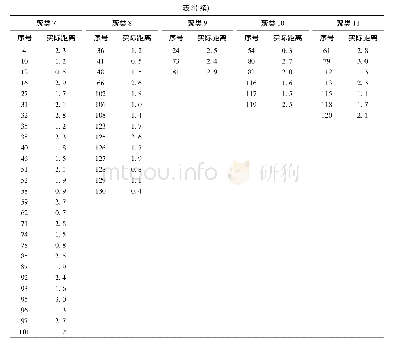
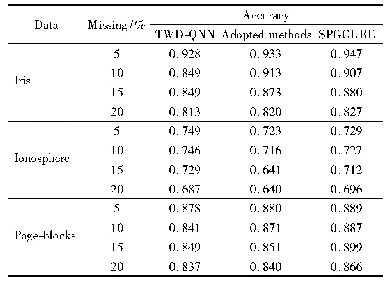
结合如图4计算得到属于第二类的信息熵权重来看,不难发现样本中的1至50的数据点有着很大的熵权值,这表明了第1类与第2类数据之间存在着较大的相似距离.而第2类、第3类数据点在权重值上非常靠近,只有如x96、x100等极少数的数据点分离得较开,但是权重系数又非常的小,这足以表明改进后的算法有着良好的聚类效果,见表2.
| 图表编号 | XD00132214400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 王红、陈功平 |
| 绘制单位 | 六安职业技术学院信息与电子工程学院、六安职业技术学院信息与电子工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}