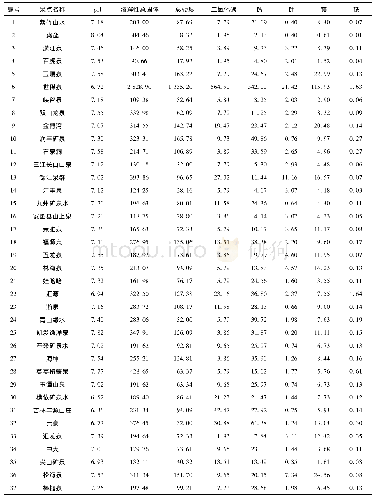
《表2 数据结构特征表(家)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中国种植类家庭农场的土地形成及使用特征——基于全国31省(自治区、直辖市)2014~2018年监测数据》
注:a.括号中的255是2014年另外一个独有样本数。
本文所用监测数据是一个5年期的混合横截面数据集(Pooled Cross-Sectional Data),由一个5年期的面板数据集(Panel Data)和一个5年期的每年独有数据集混合构成,总共三类数据。(1)5年面板数据集(下简称“面板数据”)。从2014年开始,在实际监测中,按计划每年追踪60%~80%的样本,剔除无效样本(某农场因为很多关键变量缺失或无效;或者该农场在某一年退出经营等),2014~2017年都被追踪到的样本农场大约1600家,而5年都被追踪到的农场则降为1350家,最终形成一个样本个数为6750的5年期面板数据(表2第2列)。(2)5年每年独有数据集(下简称“每年独有”)。家庭农场作为一个整体,每年都会有所发展,为了捕捉整体发展的新动向,每年在追踪监测样本(老样本)之外,再随机选取部分当年新成立的家庭农场为当年新增监测样本(新样本)。这些新增样本是上一年和下一年都没有监测的样本,是当年独有的样本,含有刻画当年家庭农场这个事物总体发展的信息,这些信息是被连续追踪的“老样本”无法包括的。剔除无效样本后,2015年独有样本569家,2018年独有样本387家。从信息“全新”这个角度讲,监测初年2014年的所有样本都是独有样本,这2823家样本农场代表了当年家庭农场发展情况;如果进一步剔除当年被追踪的农场样本等,剩下另外一个2014年独有数据(255家);在后面利用独有数据进行分析时,将基于2014年2823这个独有样本(当年最大信息集合)进行分析。最后,每年被随机抽取的独有样本混合起来形成一个样本数为4587的5年期每年独有数据集,这个数据集是典型的混合横截面数据集(表2第3列)。(3)5年混合全部样本集(下简称“全部样本”)。每年所有监测样本混合起来形成一个样本量为14623的5年期混合横截面数据集。这个数据集的信息含量最大,本文将主要依此进行分析。
| 图表编号 | XD00131523700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.05 |
| 作者 | 郜亮亮 |
| 绘制单位 | 中国社会科学院农村发展研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}