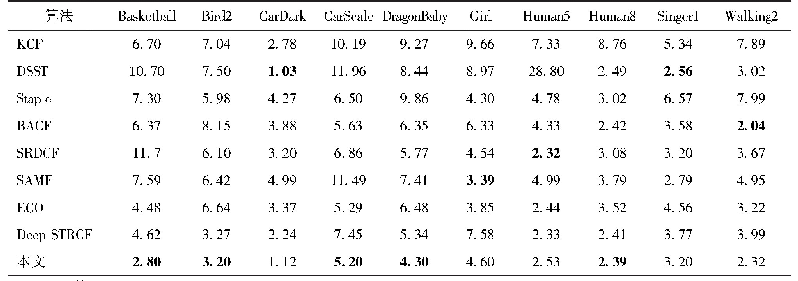
《表3 在VG数据集上不同算法模型效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
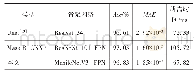
为实现视觉关系检测,首先要定位并识别出图像中的各类目标,通过目标检测模块(主要是卷积神经网络)提取包括整体图像特征、目标区域图像特征、目标位置信息特征、目标类别语义特征等作为关系检测模块的基础特征信息。关系检测模块使用这些特征作为输入,经过视觉和语义特征融合,输出预测的三元组标签以及位置。在输出模块通过有针对性的定义模型的损失函数,达到更优的训练效果。表2和表3给出了近几年使用深度神经网络框架完成视觉关系检测的方法在VRD和VG数据集上的性能表现(由于OIDv5数据集较新,暂无对比结果)。这些公开的视觉关系检测方法大都在关系检测模块上探索了不同的网络结构,小部分尝试对目标检测模块和输出模块的目标函数进行了设计。
| 图表编号 | XD00128687400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.21 |
| 作者 | 丁文博、许玥 |
| 绘制单位 | 上海汽车集团人工智能实验室、美国加州洛杉矶约巴林达高中 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}