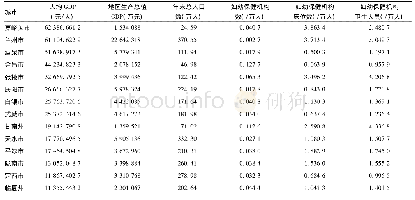
《表2 筛选数据集中影响碳排放的全部自变量的VIP值(由高到低排序)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中国碳排放影响因素的变量筛选研究——基于PLS-VIP方法》
图2显示,在利用PLS-VIP方法筛选变量的过程中,发现RMSECV随入选变量个数的增加,其值经历了由急剧减小再到逐渐增大的变化过程,并且在入选变量数为7时,RMSECV达到最小值,表明入选变量数超过或小于此临界值时,会产生信息冗余或降低建模效果。因此,初步确定变量数m=7作为要筛选出的变量个数;再结合筛选数据集中自变量的VIP排序(表2)以及变量入选标准(即VIP>1的变量和VIP<1的第一个变量可作为入选变量),最终筛选出影响碳排放量的7个自变量分别为人口数量(x1)、人均GDP(x2)、城市化率(x3)、第三产业比重(x5)、能源强度(x6)、人均能源消费量(x7)和煤炭消费比例(x8),而工业化水平(x4)、石油消费比例(x9)和天然气消费比例(x10)对碳排放的影响较小,这可能与我国工业化所处的发展阶段以及长期煤炭占能源结构的主导地位密切相关。同时,碳排放影响因素的变量筛选结果表明(表3),基于PLS-VIP方法得到的决定系数Rc2为0.996,均方根误差RMSEC为0.025,且潜变量的累积交叉有效性更接近于1,预示着用筛选出来的变量建立模型比用传统PLS方法建立的模型能提供更准确、灵敏的信息。此外,PLS-VIP方法筛选的输入变量数较传统PLS方法减少了3个(表3),明显降低了模型的复杂度和随机波动,有利于提高模型的稳定性。
| 图表编号 | XD00118291000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.15 |
| 作者 | 刘贤赵、杨旭 |
| 绘制单位 | 湖南科技大学资源环境与安全工程学院、湖南科技大学资源环境与安全工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}