《表2 分类模型建模数据(部分)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
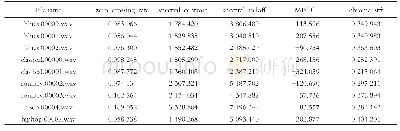
(2)构建样本分类模型,如图4所示红色虚线框部分:计算测试数据集中每个样本,采用“MB,MR,MM,ML”4种模型进行预测的相对误差,选择相对误差最小值作为该样本下的预测最优算法,并给每个样本添加取得最优预测结果的算法类别作为标记,其中BP、RBF、MLP、LSSVM分别标记为1、2、3、4,形成分类样本数据集。部分数据分类结果如表2所示。其中,得到各算法最优类别标记个数分别为属于1类别个数有30组;属于2类别个数有47组;属于3类别个数有95组;属于4类别个数有128组。从各类别标记数量来看,没有算法能够对不同样本均得到最优预测结果;在增加标记之后的测试样本数据集中随机选取200组样本作为C4.5算法建模的训练集,建立分类预测模型,在图4中用黑色点划线表示。其中,根据实验法得到C4.5算法中置信因子最优值为0.2。
| 图表编号 | XD00118105400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 唐振浩、张宝凯、曹生现、王恭、赵波 |
| 绘制单位 | 东北电力大学自动化学院、东北电力大学自动化学院、东北电力大学自动化学院、东北电力大学自动化学院、东北电力大学自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}