《表5 加入编码遮罩的效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表5给出了添加编码遮罩的实验结果。星号表示实验结果具有统计显著性。由表5可以看到,虽然词对齐的错误率仍然要高于基于循环神经网络的机器翻译模型,但是通过添加编码遮罩的方式,确实能够让基于自编码网络的机器翻译模型学习到更好的词对齐。此外,虽然编码遮罩减少了编码器所使用的信息,但是在THU语料库上的翻译效果并没有受到太大的影响。对于NIST MT 02语料库,BLEU得分在一定程度上甚至还有所上升,这一点就超出了设计预期。因此,分析后可知,暴露范围的不同确实是造成自编码网络的神经机器翻译模型无法成功学习到词对齐的原因之一。
| 图表编号 | XD00116250500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 马春鹏、赵铁军 |
| 绘制单位 | 哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




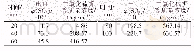

{kind=link}