《表2 不同的AdaBoost.R算法阈值的选择》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进的AdaBoost.RS算法的烧结终点预报分析》
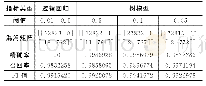
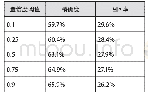
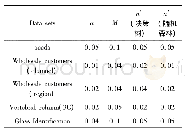
集成学习的主要思想是将多个学习器进行结合以获得比单一学习器更优越的泛化性能。AdaBoost算法是集成算法中Boosting族算法的一种,由Freund Y和Schapire R E在1997年提出[13],初始的AdaBoost算法仅用于二分类问题,AdaBoost.M1与AdaBoost.M2适用于多分类问题,Freund Y等在AdaBoost.M2算法的基础上提出了可用于回归问题的AdaBoost.R算法。AdaBoost.R算法即将回归序列的目标值映射为yi∈Y=[0,1],选取阈值y∈Y将回归问题转化成分类问题。Drucker H引入损失函数对AdaBoost.R算法进行改进,提出AdaBoost.R2算法[14],但是试验证明样本数据的噪声和异常值对AdaBoost.R2算法的结果影响较大,且当平均损失函数值大于0.5时,弱学习器的训练将会停止。针对AdaBoost.R2算法的不足,2004年,Solomatine D P和Shrestha D L[15]提出AdaBoost.RT(R指回归,T指阈值)算法,即通过引入阈值变量来判断弱学习器样本训练的好坏,对于绝对相对误差大于阈值的样本,增大权重并重点学习。阈值的准确选取是AdaBoost.RT算法的关键,Shrestha D L和Solomatine D P的试验证明[16],阈值取0~0.4时算法比较稳定。为了准确选取阈值,2009年,田慧欣等[17]提出自适应选取阈值的方法,即通过比较上一次与本次的弱学习器训练数据的均方误差(root mean square error,简称RMSE)大小来调整阈值大小,但是这种更改阈值的方法依赖于初始阈值的选取。2017年,田慧欣等[18]引入松弛变量ε来判断训练结果的好坏,提出AdaBoost.RS算法。不同AdaBoost.RT算法中阈值确定方法的比较见表2。
| 图表编号 | XD00109594800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 汪森辉、李海峰、张永杰、邹宗树 |
| 绘制单位 | 东北大学冶金学院、东北大学冶金学院、东北大学多金属共生矿产生态利用教育部重点实验室、奥博学术大学化工学院热流工程研究所、东北大学冶金学院、东北大学冶金学院、东北大学多金属共生矿产生态利用教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}