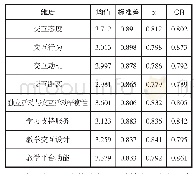
《表1 主题异样度计算:多域识别构建监督学习模型检测网页暗链》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
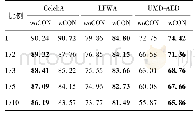
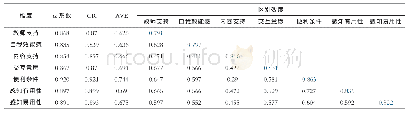
在模型训练检测阶段,通过敏感域识别后提取出了风险文本和安全文本,分别使用LDA算法抽取两类文本的主题集,使用表1主题异样度算法计算得到prob。如表1所示,输入值为安全文本safe_text、风险文本risk_text、阈值threshold,输出为主题异样度prob。步骤3和4对原始文本做去噪操作,具体为过滤掉特殊字符乱码等噪音。步骤5和6使用LDA算法提取安全文本和风险文本主题词集,步骤7和8根据不同主题类别中匹配的主题词数量得到安全主题类别saf_category、风险主题类别risk_category,步骤9和10将主题词数量与对应权重W乘积累加并做归一化操作得到匹配率,步骤11-16根据匹配率和threshold大小计算最终主题异样度pro。
| 图表编号 | XD00106813400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.10 |
| 作者 | 孟雷 |
| 绘制单位 | 上海斗象信息科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}