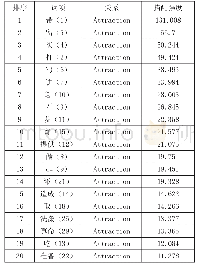
《表1 搭配构式分析中词X和构式Y共现频率示意图》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《“-ly副词+speaking”构式语义的语料库研究》
Jones和Waller认为说话者通过使用某一构式可以折射出其对某一事件的态度[9]72。多数语料库在线网站及语料分析软件均以频率作为最基本的检索方式。Widdowson曾指出,在语言研究中,频率有时并不能完全反映以及结构的典型性和相对认知凸显[10]。本研究基于此进行了进一步思考,并尝试在词汇搭配频率与语义之间寻求一种更为科学的量化方法。互信息值(mutual information,缩写为MI值)也是语料库语言学中一种较为常见的计算词汇搭配强度的方法。一般来说,MI值越大,说明搭配强度越大。在实际操作中以MI值3为临界值,MI值大于3的搭配词可视作显著搭配词[11][12]。一些在线语料库及语料分析软件均提供此方法。而互信息值最大的不足就是对临界特征的概率比较敏感,且它没有考虑特征在文本中发生的频度,因而此方法经常倾向于选择稀有特征[13]。通过采用简单的互信息值计算,工作语料库中的一些低频数据确实获得了更多的关注,而这并不是实验设计的初衷。结合本试验工作语料库的数据特点,为了更为科学地论证和探索“-ly副词+speaking”构式的语义特征以及其在二语学习者中的运用,本研究选用对数似然比(Log Likelihood Ratio)的计算方法对语料数据进行重新评估。首先,与互信息算法相比,该方法在处理低频单词时,其对分类的贡献没有过分放大且低频单词对分类的贡献计算更为准确。其次,该算法在考虑低频单词对分类结果产生正面影响的同时,能较好地控制其对分类产生的负面影响[14]。本研究中的对数似然比计算由Gries(2014)[15]的搭配构式分析(collostructional analyses)实现。该分析方法基于R语言(3.4.1版本),具有三个子程序,分别为共现词素分析(collexeme analysis)、区别共现词素分析(distinctive collexeme analysis)以及共变共现词素分析(co-varying collexeme analysis)。本研究所采用的是共现词素分析。该子程序需要研究者提供(a)工作语料库的总容量、(b)工作构式在该语料库中的总频率、(c)语料库中检索到的“-ly副词+speaking”构式类别以及(d)在“-ly副词+speaking”构式中出现的每一个副词在语料库中的使用频率。该程序通过对数似然比计算出工作构式的搭配强度并将计算结果按照搭配构式强度(collostruction strength)的大小进行排序,该数值越大,则表明对应的单词与“-ly副词+speaking”构式的语义关联越密切。以表1为例,若词X在构式Y中出现的频率为A,而其在语料库中其他地方出现的频率为B,那么则有:
| 图表编号 | XD00101493800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 谢冰、胡永近 |
| 绘制单位 | 宿州学院外国语学院、宿州学院外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}