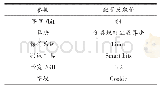
《表2 实验数据:云计算平台上的Canopy-Kmeans并行聚类算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《云计算平台上的Canopy-Kmeans并行聚类算法研究》
在本次实验内容中,如果增加目前计算机硬件资源,计算机系统中的计算数据规模相同,表2为实验数据。通过表2可以看出,每条计算得到的数据都是通过四维状态下数值类型组合构成,计算模型的计算程序也通过既定标准生成5种计算类型。对比规模大小完全相同的计算数据,在计算过程中如果出现增加节点的情况,系统完成计算任务所消耗时间会减少,以此实现计算大规模数据实效性。由此可知,在大规模数据计算的过程中,利用节点的增加能够提高系统的计算成效。
| 图表编号 | XD0096183000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 孙秀娟 |
| 绘制单位 | 潍坊科技学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}