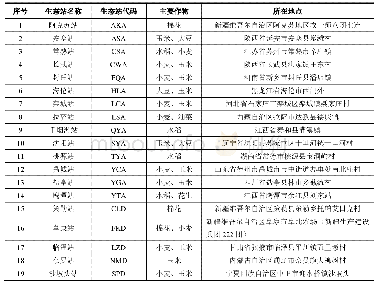
《表1 Bakeoff2005数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验数据采用由Bakeoff2005提供的PKU,MSR,CITYU,AS四种数据集,四种数据集的分词标准各有不同。PKU是由北京大学计算语言学研究所提供的语料库,其分词特点是姓名中姓和名要分开,组织机构等在语法词典中的直接标记,大多数短语性的词语先切分再组合。MSR是微软亚洲研究院所提供的语料库,其分词特点是由大量的命名实体构成的长单词。AS是由台湾中央研究院提供的语料库,分词规范与北大制定的分词规范类似,同时也与台湾地区的语言使用习惯相关。CITYU是由香港城市大学提供的语料库,分词规范受香港地区的使用习惯影响。数据集规模如表1所示。其中随机选取训练数据的90%作为训练集,10%作为开发集。所有的数据在输入前需要经过预处理,将英文字母替换成X,数字替换成0。
| 图表编号 | XD0091815000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 王星、李超、陈吉 |
| 绘制单位 | 辽宁工程技术大学电子与信息工程学院、辽宁工程技术大学电子与信息工程学院、辽宁工程技术大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}