《表2 项目—类别属性矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于类别属性的数据,通常利用0和1作余弦相似度计算。如表1所示,I1的类别属性集合为{1,1,1,0,1},I3的类别属性集合为{0,1,0,0,1},通过类别集合计算I1和I3两者之间的相似度为0.707,但分析表1可知,I3的平均分为4.5,I1的平均分为1.5,说明影片3远比影片1好看,更加受到用户的喜爱,但是得到两者之间的相似度有点差强人意;再看一个例子,I4的类别属性为{0,1,1,0,0},通过类别集合计算I3和I4的相似度为0.816,反观影片4的评分远远低于影片3的评分,直接根据类别属性计算两者之间的相似度这种方法粒度太粗。分析表2,出现的频次有多有少,属性A2和A5出现的次数较为频繁,属性A4出现的频次较少,那么属性出现的频次是否会影响到项目相似性的计算呢?对于电影来说,影片可以分为喜剧和悲剧,喜剧分为讽刺喜剧、欢乐喜剧、幽默喜剧、无厘头喜剧等小类,因此大类属性—喜剧这个属性出现的频次相比于其小类出现的频次要高,那么在计算相似度时赋予每种属性的权重应该有所不同。人们常说,“物以稀为贵”,所以出现频次少的属性应该赋予更高的权重。为了提高计算效率,很容易联想到将属性出现的总频次的倒数作为权重值,于是得到如表3所示的矩阵。
| 图表编号 | XD0090307900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 周强、胡燕 |
| 绘制单位 | 武汉理工大学计算机科学与技术学院、武汉理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


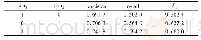



{kind=link}