《表3 用户属性的类别区间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
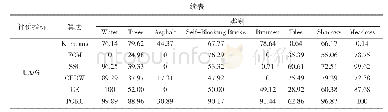
通过数据属性选择、按照约束条件去除不完整数据来实现数据的预处理,然后利用K-means算法进行聚类。k-means聚类算法的基本思想是一般预先设定需要聚类的个数k,k一般取值5-13之间,且为整数,然后根据统计量将数据集划分到这k个簇中,将簇的均值作为簇中心,不断通过迭代算法使其收敛,最后选择合适的分类用户当做目标,得到结果如表3所示。
| 图表编号 | XD0014771900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.15 |
| 作者 | 任小强、杨玉忠、张仁轩、王晓龙 |
| 绘制单位 | 中国移动通信集团甘肃有限公司兰州分公司、中国移动通信集团甘肃有限公司兰州分公司、中国移动通信集团甘肃有限公司兰州分公司、中国移动通信集团甘肃有限公司兰州分公司 |
| 更多格式 | 高清、无水印(增值服务) |
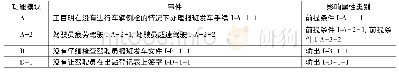




{kind=link}