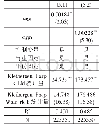
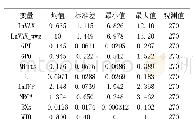
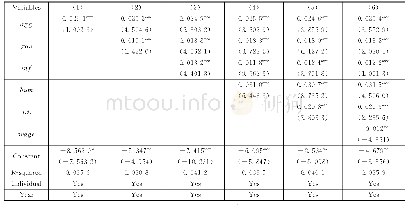
《表5 2SLS计量结果:产业集聚与企业出口国内附加值:GVC升级的本地化路径》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
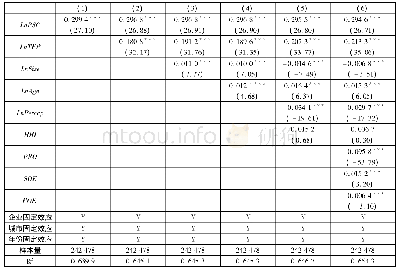
《产业集聚与企业出口国内附加值:GVC升级的本地化路径》
注:Kleibergen-Paap统计量中{·}内的数值为Stock-Yogo检验10%水平上的临界值。限于篇幅未报告控制变量估计结果,可向作者索取。
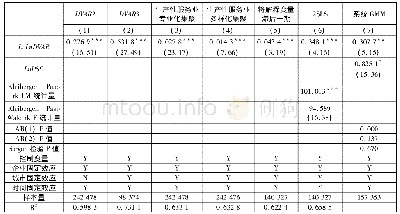
一个合适的工具变量不仅要与内生变量相关,还必须满足与误差项不相关的排除性约束(exclusion constraint)或者说外生性条件(Angrist and Pischke,2009)。通常来说,为保证外生性条件,相对固定的人口、地理或历史等变量是较好的工具变量,因此,与Ciccone和Hall(1996)、Li和Lu (2009)、Combes等(2010)以历史人口数据作为产业集聚工具变量的做法一致,本文选取1993年县级层面人口数对数值 (15)为产业集聚的工具变量。表5中的模型(5.1)报告了相应的两阶段最小二乘法(2SLS)估计结果。从中可知,Kleibergen-Paap rk LM检验在1%水平上拒绝了工具变量识别不足的零假设,Kleibergen-Paap Wald rk F统计量大于Stock-Yogo检验10%水平上的临界值,拒绝了工具变量是弱识别的原假定,这表明工具变量与潜在的内生变量之间具有较强的相关性。进一步地,我们也对产业集聚的稳健性指标,即包括自身就业人数的产业集聚指标(agg1)进行了类似的内生性处理,模型(5.2)结果显示,此时仍通过了识别不足和弱识别检验。综上而言,本文选取的工具变量是较为合理的,表5中各个模型的估计结果是可取的。结果显示,即使考虑了可能存在的内生性问题,产业集聚对企业出口DVAR仍具有显著的促进作用,本文的核心结论依旧成立。
| 图表编号 | XD0087849300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.15 |
| 作者 | 邵朝对、苏丹妮 |
| 绘制单位 | 南开大学经济学院国际经济研究所 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}