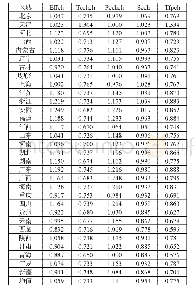
《表2 普惠金融指数及其各指标相关系数矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:a为以现提出的计算方法和以矩估计确定权重而计算出的IFI;b为以Sarma提出的计算方法和以变异系数确定权重而计算出的IFI;c为以现提出的计算方法和以变系数确定权重而计算出的IFI。
现所采用的是2006年到2015年我国31个省份、直辖市的面板数据,数据基本来源于《中国统计年鉴》、各省《统计年鉴》《区域金融运行报告》和《金融统计年鉴》。从普惠金融评价体系中各指标的相关系数矩阵(表2)可以看出,如果将所有指标控制在同一个方程会导致严重的多重共线性,直观地将其分为两组,分别进行计算可以缓解这一问题。以G1、G4、G7和G9为一组,以G2、G3、G5、G6和G8为另一组。在没有找到有效的工具变量之前,且以自身作为工具变量,即使如此,与变异系数赋权法相比,计量赋权的优点在于三点。第一,符合实际情况和权重本身的内涵。第二,考虑了其他因素的影响,至少在此将个体特征带来的影响考虑进来,虽然存在着内生性,但从相关系数矩阵来看似乎并不严重,且分成两个方程组的形式保证了对信息的完整利用又降低了多重共线性的问题。第三,根据回归系数的设定,误差是可以控制在一定范围的,而基于变异系数计算出来的权重的误差是不可控制的。
| 图表编号 | XD0087382600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 林腾雄、耿庆峰、娄磊 |
| 绘制单位 | 闽江学院经济与管理学院、闽江学院经济与管理学院、闽江学院经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}