《表2 MirFLickr25k数据集实验结果(38个类)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
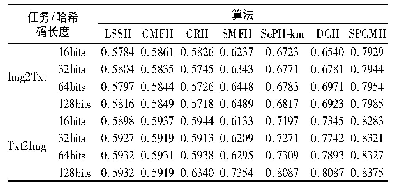
24个类别数据集的实验结果如图3所示,其中,绝大多数标签类别的识别准确率均比MVAIACNN模型要高。最终的平均识别精确率为81.1%,相较于MVAIACNN模型(66.6%)的mAP提高了14.5%。38个类别数据集的实验结果如表2所示,从表中可以看出,大多数标签的识别精确率相较于LDA、SVM、DBN[26]、AIACNN(MVAIACNN)[27]相比,都有了明显的提升;本文方法最终的平均识别精确率的结果为78.2%,相比于AIACNN(MVAIACNN)最好的效果62.4%提高了15.8%,相对于只使用主网络模型denseNet的效果77.4%提升了0.8%。由于该数据集图像来源于社交摄像网站,大多数图像所包含的内容十分丰富,每张图像的平均标签个数为5~7个,因此,该数据集存在着较多的标签依赖关系,例如:1)女性(female)与室内(indoor)、食物(food)与室内、动物(animals)与室内都存在共生关系;2)天空(sky)与建筑(structures)、太阳(sunset)与建筑、交通工具(transport)与建筑都存在共生关系;3)河流(river)与天空、云(clouds)与天空都存在共生关系。由于标签之间的语义依赖关系十分多样,从表中可以看出,相对于只使用denseNet模型的识别准确率,本文方法单个标签的识别准确率绝大多数都有所提升,最终的平均识别准确率也相应的提升。这说明融合注意力机制与语义关联性的方法可以通过学习标签之间的依赖关系来提升最终的多标签分类效果。
| 图表编号 | XD0087180400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 薛丽霞、江迪、汪荣贵、杨娟 |
| 绘制单位 | 合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}