《表4 两种算法在Iris数据集上的结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《一种非独立同分布下K-means算法的初始中心优化方法》
从图1中可以看出非独立同分布下的聚类准确率整体要高于独立同分布下的结果.其中,Iris数据集在非独立同分布下的CR-K算法低于独立同分布下的OR-M M K算法以及文献[5-7]中的算法主要是因为其受初始中心点影响较大,不当的初始中心点可能会导致聚类结果准确率较差.为了进一步的验证,本文对Iris数据集下的OR-K算法和CR-K算法进行详细对比,具体如表4所示.
| 图表编号 | XD0079869900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 潘品臣、姜合、吕奕锟 |
| 绘制单位 | 齐鲁工业大学(山东省科学院)计算机科学与技术学院、齐鲁工业大学(山东省科学院)计算机科学与技术学院、齐鲁工业大学(山东省科学院)计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



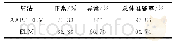


{kind=link}