《表3 3种算法增强后的平均输出SNR和PESQ结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
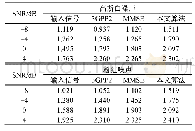
选取SNR和PESQ作为各种算法增强语音的性能评价指标。表1和表2分别列出了3种算法在SNR和PESQ值两个方面的对比结果。通过对表中所示的结果分析,所提出的算法在改善SNR和PESQ值方面显然优于其余两种对比算法,特别是对于低信噪比为-5dB时,依旧取得很好的增强效果。为了更佳地突出说明所提出算法的优点,分别给出了不同字典学习算法的语音增强后的平均SNR和PESQ值的对比结果,如表3所示。从统计结果分析可以计算出,当输入的信噪比分别为-5dB、0dB和5dB时,文中提出的区分性联合稀疏字典交替优化的语音增强和KSVD算法相比较,输出信噪比平均提高了10.00dB,6.82dB,4.25dB,PESQ值平均提高了0.87、0.92和0.98。与联合字典算法比较,输出信噪比提高了3.80dB、2.82dB和1.25dB,PESQ值提高了0.68、0.70和0.58。实验证明,所提出的算法在各种信噪比的情况下均可以取得很好的可懂度,从听觉效果上来看,语音听起来更加舒适自然。
| 图表编号 | XD0078787900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.20 |
| 作者 | 贾海蓉、王卫梅、王雁、裴俊华 |
| 绘制单位 | 太原理工大学信息与计算机学院、太原理工大学信息与计算机学院、太原理工大学信息与计算机学院、太原理工大学信息与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}