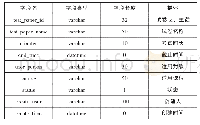
《表1 p_test仿真结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
第一,确立训练组和仿真组。将中国石油、中国石化和中国海油2007—2013年数据训练组输入向量p,由层次分析法(A HP)确立的权重得到各年指标期望值作为导师向量t。然后对所有数据归一化处理备用,图1为已经确定好的训练组输入向量p、仿真数据组p_test和期望输出向量t。第二,确定隐含层的节点数。通过训练时间和识别率来判断节点数的选择是否合适,在实际操作过程中采取经验公式或者与作为参考,其中m为输出神经元数,n为输入神经元数,为[1,10]之间的常数。本文10个指标作为输入层向量,输出层为1个,经过反复多次训练来比较隐含层的节点数对结果影响的误差值,选择使最终整体误差值最小的N作为隐含层神经元的个数。第三,确定网络训练的方法和具体代码。调用BP神经网络函数newff,设置输入层输入向量p,期望输出向量t,隐含层神经元个数为4个,采用10-4-1结构。中间隐含层采用tansig函数,输出层采用purelin函数,采用标准的梯度下降算法t rainlm,目标误差为0.00001,误差显示步长25,最大训练步长数6000步。训练结果gradient是误差曲面的梯度,当梯度达到0.0000942时,训练结束。Mu是算法里面的一个参数,Performance是Mean Squared Error(均方误差),0.0145是初始值,训练过程迭代得到0.000000123,小于目标值0.00001,训练过程结束。第四,测试数据。比较BP神经网络训练的实际输出值与导师向量,误差在可接受范围之内,该网络可以用于仿真测试。对三大石油企业2014—2015年数据p_test进行逐一仿真,得到如表1结果。
| 图表编号 | XD0076362700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.15 |
| 作者 | 钟书丽、杨洋、高庆欣、余晓钟 |
| 绘制单位 | 西南石油大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}