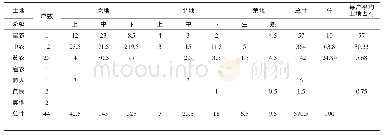
《表6 各标签占有比以及性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表5可以看出加入Dropout之后,CRF层对非结构化文本简历的解析结果有一定提升,F1-score增加了0.97%,其主要原因是在对非结构化简历进行解析时,Dropout阻止了某些特征只能在其特定特征下才有效果的情况。在模型加入Dropout的基础上加入预先训练的字向量,模型的性能提升了将近2.3%。由表6表示的各个标签占有比以及性能可知,本文提出的利用BLSTM对字序列进行建模的方法对于性别、姓名等短信息实体具有一个很好的识别效果。
| 图表编号 | XD0074396600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.16 |
| 作者 | 陈毅、符磊、张剑、黄石磊 |
| 绘制单位 | 重庆邮电大学光通信与网络重点实验室、北京大学深圳研究院、深港产学研基地深圳市智能媒体和语音重点实验室、安徽大学计算智能与信号处理教育部重点实验室、北京大学深圳研究院、深港产学研基地深圳市智能媒体和语音重点实验室、北京大学深圳研究院、深港产学研基地产业发展中心、深港产学研基地深圳市智能媒体和语音重点实验室、深港产学研基地产业发展中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}