《表2 模拟数据各比例非全长读段计算结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《保留非全长读段的ISO-seq数据转录组表达分析》
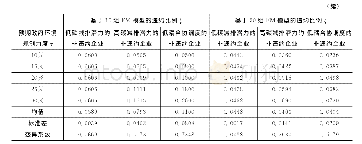
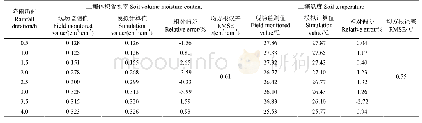
从表1可以看出当读段长度越长时,非全长读段的数量就越多。因此本文在模拟数据集上做了非全长读段不同占比的对照实验,将100条全长读段按25%,50%和75%的比例随机抽取,并作随机打断,产生相应比例的非全长读段,剩下的全长读段作为对照组,全长读段加上非全长读段作为实验组。在各比例的对照实验中,实验组与对照组均使用DSIDP方法计算结果,并采用计算值与真实值之间的欧式距离作为误差度量。如表2和表3所示,在加入非全长读段数据后,各比例实验的表达水平计算值均比只使用全长读段数据更为精确,表中FL(Full length)表示全长读段,nFL (non-full length)表示非全长读段。值得指出的是,在非全长读段数据占75%的比例时,误差有大幅度的下降,但误差本身仍然要比其他比例只用全长读段数据结果值大,这说明在计算异构体表达水平时,保留非全长读段数据能够降低只使用全长读段数据的计算误差。另外,模拟数据集构建的假设前提是该基因的所有异构体均来自细胞内当前表达且被测序到的mRNA分子,与注释库中的信息无关,因此可以认为当细胞内出现新型异构体时,也能被DSIDP预测出。例如,假设t4为新型异构体,且100条读段数据中包含有t4,则会被DSIDP预测出其结构和表达值。
| 图表编号 | XD0074249400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 刘学军、瞿锡垚、张礼 |
| 绘制单位 | 南京航空航天大学计算机科学与技术学院、南京航空航天大学计算机科学与技术学院、南京林业大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}