《表1 MCF-7数据集读段统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《保留非全长读段的ISO-seq数据转录组表达分析》
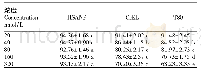
图1显示了ISO-seq数据中全长读段和非全长读段长度分布直方图,图中数据来自PacBio公司公开数据集MCF-7 (http://www.pacb.com/blog/data-release-human-mcf-7-transcriptome/)。本文统计了6个cell的原始数据(如表1所示),其中按照ISO-seq技术的size-selection原则,对样本长度1~2 Kb,2~3Kb和>3 Kb三个范围的Cell各选取两个。从统计结果可以看出全长读段和非全长读段的长度分布具有相似的模态,数据多集中在长度为1~3 Kb的区间内,这说明非全长读段数据也具有远超过RNA-seq数据的长度,从第三代测序数据超长读长这一本质特征来说,非全长读段与全长读段一样,也包含关于异构体的有效信息。并且随着样本序列长度的增加,非全长读段也随之增加,并达到接近60%。如果在异构体的构建中不考虑这部分数据,相当于丢弃了大部分实验数据。因此将ISO-seq数据应用于转录组学研究领域时,保留非全长读段具有重要意义。
| 图表编号 | XD0074249300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 刘学军、瞿锡垚、张礼 |
| 绘制单位 | 南京航空航天大学计算机科学与技术学院、南京航空航天大学计算机科学与技术学院、南京林业大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
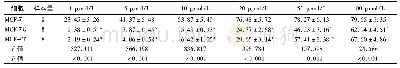



{kind=link}