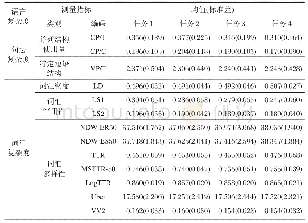
《表3 罪名预测任务宏平均各项指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
虽然MTL-TRank和MTL-TFIDF模型在性能上有提升,但是根据实验结果来看,2个任务在宏平均F值上面提升的幅度并不是十分明显。通过对构建的罪名关键词表仔细研究发现,罪名关键词表中有一定数量的关键词在大多数罪名中同时存在,导致不能够有效地区分易混淆罪名。由表3可以发现:MTL-TFIDF模型的精确率指标要明显高于MTL-TRank模型的,但是召回率指标却低于MTL-TRank模型的。通过对罪名关键词表的观察和对实验结果的研究分析,本文提出采用TFIDF和TextRank方法融合的方式再次自动构建罪名关键词表,并且把关键词融入到多任务学习模型中得到MTL-Fusion模型。表2的实验结果表明,MTL-Fusion模型在这2个任务上的各项评价指标都要比MTL模型的高出1%~2%。实验结果表明,融入罪名关键词信息的多任务学习模型能够进一步提升罪名预测和法条推荐的性能。
| 图表编号 | XD0072425100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 刘宗林、张梅山、甄冉冉、公佐权、余南、付国宏 |
| 绘制单位 | 黑龙江大学计算机科学技术学院、黑龙江大学计算机科学技术学院、黑龙江大学计算机科学技术学院、贵州财经大学信息学院、黑龙江大学计算机科学技术学院、黑龙江大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}