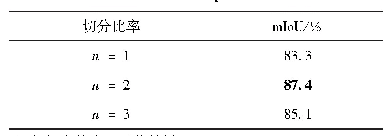
《表8 不同切分策略的HMAN模型结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中文比较关系的识别:基于注意力机制的深度学习模型》
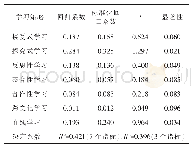
从表7可知,句子数量与识别效果成反比,句子平均长度与识别效果成正比,即句子的数量越少,句子的平均长度越长,识别的效果越好。这是因为单个句子较长、句子数量较少的评论文本通常包含比较完整的句子结构,模型训练相对简单,核心成分易识别。句子长度和数量都被评论文本的切分方式所控制,本文对评论采取了两种策略的切分方式:第一种按照固定长度进行切分,长度超过阈值的评论只保留前一部分的内容,长度不足的以“UNK”标记;第二种按照句号等标点符号进行切分。结果如表8所示。
| 图表编号 | XD0072253400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.24 |
| 作者 | 朱茂然、王奕磊、高松、王洪伟、郑丽娟 |
| 绘制单位 | 同济大学经济与管理学院、同济大学经济与管理学院、中国信息安全测评中心、同济大学经济与管理学院、聊城大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}