《表5 不同算法的分类精度 (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
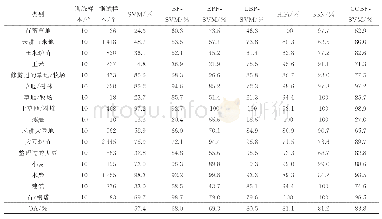
所有的数值属性首先都需要经过标准化处理到[0,1]区间.实验中设置的邻域参数δ表示邻域半径大小,δ以步长0.02在0~0.5变化.通过调控邻域参数的大小,可以有效控制各属性对样本的区分能力的差异.由于不同的算法获得最佳分类精度的特征子集不同,本文所展示的分类精度都是最佳分类精度,具体实验结果如表5所示,表中加粗的数据表示该算法测试的对应数据集的分类精度最高,可以看出,基本上所有算法对上述六个医疗数据集进行属性约简之后,分类精度对比原始精度都有所提高,其中FDM算法略优于另外几种算法.
| 图表编号 | XD0071371000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.30 |
| 作者 | 李藤、杨田、代建华、陈鸰 |
| 绘制单位 | 中南林业科技大学物流与交通学院、湖南师范大学智能计算与语言信息处理湖南省重点实验室、国防科技大学系统工程学院、湖南师范大学智能计算与语言信息处理湖南省重点实验室、中南大学湘雅医院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}