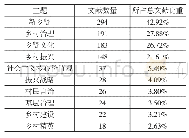
《表1 部分文献中出现的密文特征》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
观察表1,可以看到上述特征维数均在100以上,个别特征维数已经超过10万维.在机器学习领域,特征维数的提高通常会增加数据分析的存储开销与运行时间消耗.在机器学习领域,特征工程[14]的一个重要内容就是筛选信息量更多、灵活性更强的特征,从而能够在简单模型训练中也能得到优秀的结果.基于机器学习的密码体制识别任务,同样需要关注密文特征提取方式的改进以提高复杂数据环境下的识别效率.然而由于密数据通常具有较高的随机性,如何提取有效的密文特征、密文特征构建方法的创新,国内外关于该方面的公开研究较少,密文特征提取方式较为简单,因此特征所包含的密文信息有限.
| 图表编号 | XD0070792000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 赵志诚、赵亚群、刘凤梅 |
| 绘制单位 | 信息工程大学数学工程与先进计算国家重点实验室、信息工程大学数学工程与先进计算国家重点实验室、信息保障技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}